LRU Cache簡介
LRU(Least Recently Used Cache)
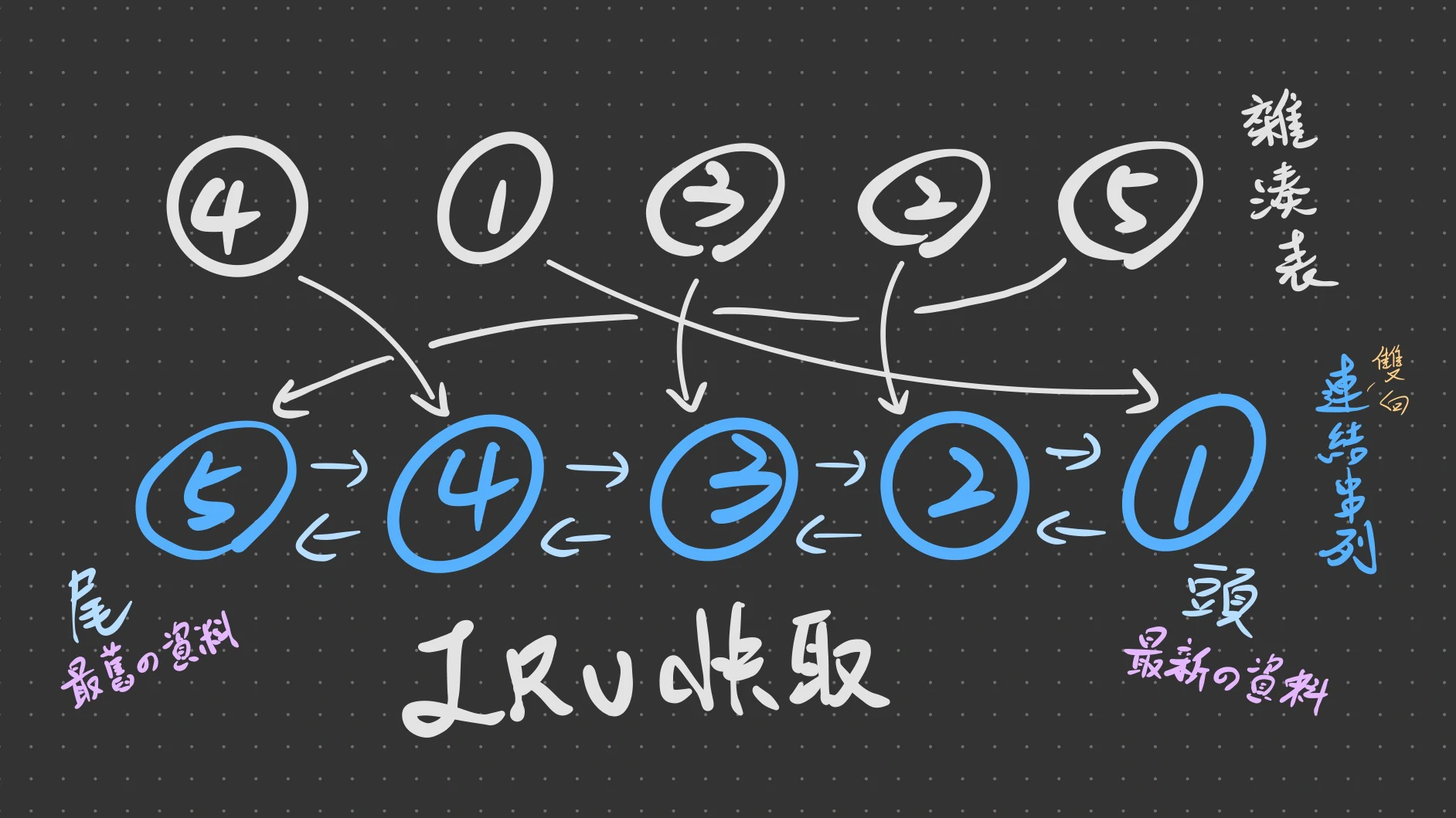
是一種快取的機制,他的概念是儲存最近用過的內容,並且根據「某種原則」來取代掉舊的資料。一個基本的LRU Cache會透過 Hash Map與 Double Linked List 來搭配實做。
原則
- 如果資料越常被使用,就會被擺在List愈前方的位置
- 如果快取滿了,則會從 List最末端元素開始移除
要點
LRU Cache使用了:
1. Hash Map: 用來存放Key, 以及Node
2. Double Linked List: 維護一串Link List決定誰要從Cache中被淘汰
拿資料的情境
- 如果Key有在Cache之中:
- 透過Hash Map找出該key的節點位置
- 把這個節點從Lru的連結串列中找出來並移除
- 把這個節點重新插入到連結串列的開頭
- 回傳Key所對應的資料
插入資料的情境
- 如果key有在快取內:
- 找出舊的key節點所在的位置,並把他從連結串列移除
- 產生新的節點Node給這個Key
- 把這個Node插入到串列的開頭
- 把Hash內的Key更新成這個Node
- 如果Key不存在:
- 判斷Cache的容量滿了沒,如果滿了:
- 把串列的最後一個元素移除
- 把Hash內的Key移除
- 沒滿:
- 直接產新的Node放到開頭
- 並且更新Hash Map
- 判斷Cache的容量滿了沒,如果滿了:
以Python實作的LRU快取範例
class QNode(object):
def __init__(self, key, value):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache(object):
def __init__(self, capacity):
"""
:type capacity: int
"""
if capacity <= 0:
raise ValueError("capacity > 0")
self.hash_map = {}
self.head = None
self.end = None
self.capacity = capacity
self.current_size = 0
def get(self, key):
"""
:rtype: int
"""
if key not in self.hash_map:
return -1
node = self.hash_map[key]
if self.head == node:
return node.value
self.remove(node)
self.set_head(node)
return node.value
def put(self, key, value):
"""
:type key: int
:type value: int
:rtype: nothing
"""
if key in self.hash_map:
node = self.hash_map[key]
node.value = value
if self.head != node:
self.remove(node)
self.set_head(node)
else:
new_node = QNode(key, value)
if self.current_size == self.capacity:
del self.hash_map[self.end.key]
self.remove(self.end)
self.set_head(new_node)
self.hash_map[key] = new_node
def set_head(self, node):
if not self.head:
self.head = node
self.end = node
else:
node.prev = self.head
self.head.next = node
self.head = node
self.current_size += 1
def remove(self, node):
if not self.head:
return
if node.prev:
node.prev.next = node.next
if node.next:
node.next.prev = node.prev
if not node.next and not node.prev:
self.head = None
self.end = None
if self.end == node:
self.end = node.next
self.end.prev = None
self.current_size -= 1
return node
整個演算法的重點只關注兩種情境,一是在Doble Linked List的開頭插入元素、二是從Double Linked List移除元素,換個方式講就只是關注head, tail兩個指標的位置要移動到哪裡。因為不會有突然插入中間的節點的情況,所以這種例外情境都不用考慮。
在雙向連結串列的開頭插入元素
如果Head不存在
直接把節點指定給Head跟Tail
如果Head存在
[...] <--> ... <---> [...] <---> Node
| | -------> |
Tail Old Head New Head
- 把Node的前一個節點指定到Head
- 把Head的下個節點指定給Node
- 把Head設定成指向Node
在雙向連結串列中移除一個元素
因為Hash Map的Value是Node的Index,所以我們有Key就可以馬上定位Node是在串列的哪個位置之中
如果Head不存在
連結串列內沒有東西,不需要移除
Head存在,要被移除的Node有prev, next (表示位置在列表中間)
有prev -> 把Prev的next指定給node的Next
有next -> 把Next的Prev指定給Node的Prev
Head存在,要被移除的Node沒有Prev也沒有Next
這個Node就是Head, Tail本身,同時表示連結串列只剩下一個元素
所以:Head = Tail = None
Head存在,要被移除的Node是Tail
把Tail指定給Tail的下一個Node
把新Tail的Prev指定給Nodne