
Postgres for Data Architects雜記
一直有計畫要深入閱讀Postgres的規劃,這篇筆記是閱讀PostgreSQL for Data Architects時隨手做的紀錄。日後有空再來整理。
Master-Slave架構
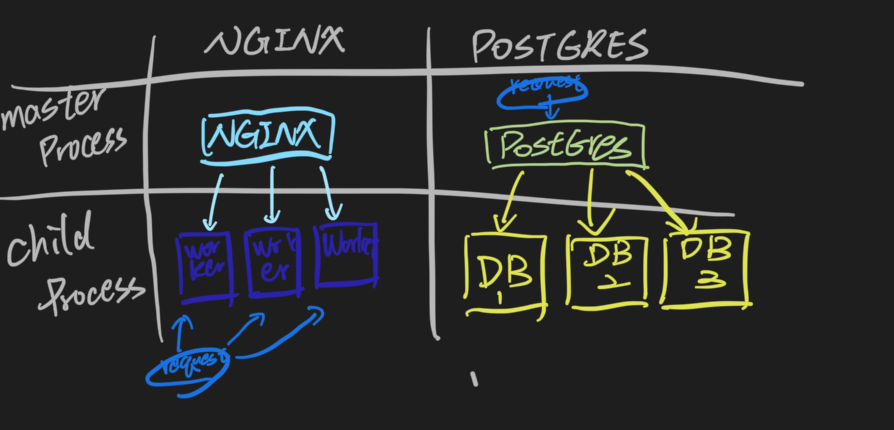
PostgresSQL的軟體架構走的是Master-Slave,PostgreSQL的Client對Daemon Process發出請求,Daemon Process產生Child Process(Backend Process)跟Client做Auth, Query..等等的動作。
跟[[../../NginX/NGINX MOC|NGINX]]不太一樣的地方在於,雖然Nginx也是Master-Slave但是Request是給Worker去負責。
Initializing a cluster
下面是自行啟動Postgres叢集的前置作業。
Postgres的Docker Image應該就是把這些東西全包了
# 自行建立一個postgres用戶
> adduser postgres
> mkdir -p /pgdata/9.3
> chown postgres /pgdata/9.3
# 在postgres的.bash_profile或是其他terminal Profile下面
# 指定好Postgres的執行檔案位置
> export PATH=$PATH:/user/local/pgsql/bin
> which initdb
/usr/local/pgsql/bin/initdb
> su - postgres
> initdb --help | more
> initdb --pgdata=/pgdata/9.3 --pwprompt
> cd /pgdata/9.3
> find ./ -maxdepth 1 -type d
./
./base
./pg_stat
./pg_clog
./pg_xlog
...
- 中間的部分記得要將Postgres的binary指定給Postgres用戶的系統Path之中
Some Important Directory
`/var/lib/postgresql/data/
常用Docker啟動Postgres的話,應該蠻熟悉這是用來存放postgres的資料
(根據書上的說法,這個資料夾並非唯一)
一開始在使用pg_ctl initdb把cluster叫起來的時候,就可以指定—pgdata的位置
/var/lib/postgresql/base
用來存放database的位置
root@613f786b1b6d:/var/lib/postgresql/data# find ./base -type d
./base
./base/1
./base/5
./base/4
./base/16384
root@613f786b1b6d:/var/lib/postgresql/data# oid2name -U devel
All databases:
Oid Database Name Tablespace
------------------------------------
16384 for-development pg_default
5 postgres pg_default
4 template0 pg_default
1 template1 pg_default
可以發現發現建立或刪除資料庫的行為,其實跟處理資料夾一樣很接近。
快取的機制
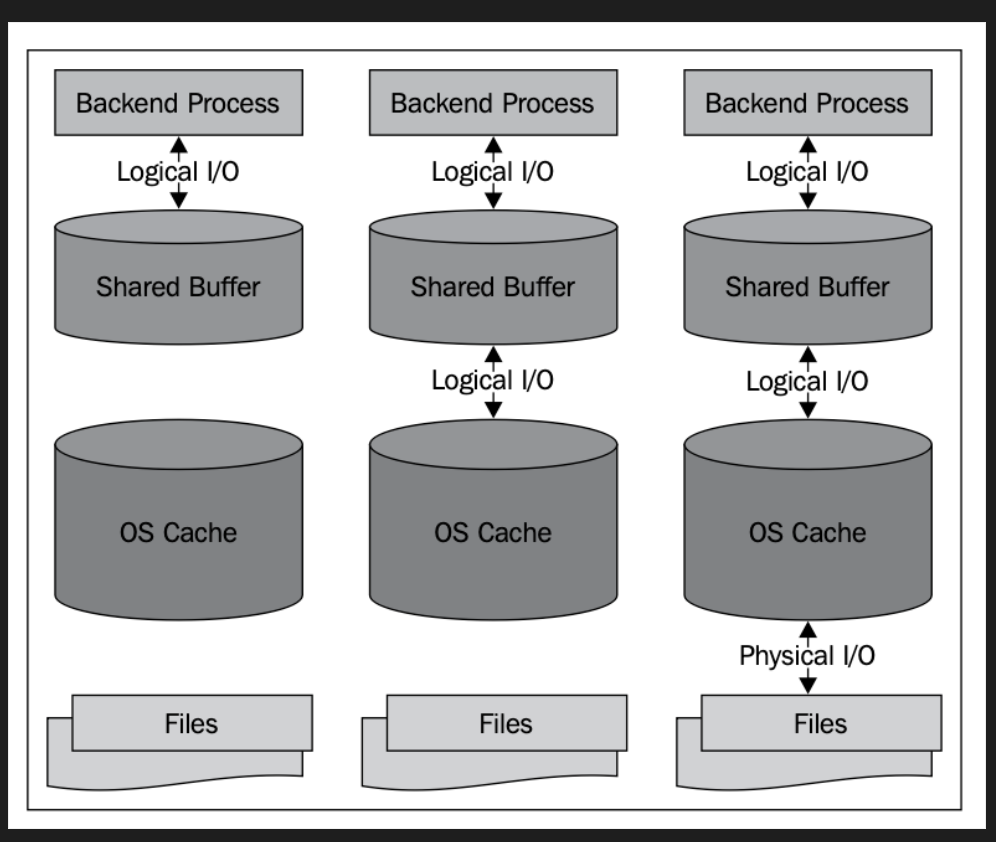
Backend Process在Query進來的時候,首先會去問問Shared Buffer,以避免頻繁地使用fseek()來開關資料庫的檔案。
- 可以透過位於postgresql.conf的shrared_bufferes來做調整
假設Buffer找不到的話,postgres這時候會去跟OS調度資料,但這個時候OS自身的block cache可能有機會存有該資料,這樣就可以馬上找到該資料減少讀取。
- 這件事情同時也暗示了,user驅動的資料讀取與寫入,其實會發生在buffer層
(即便單位時間內的transaction數量很高,實體IO也會限制這些使用相同dataset的transaction,除非有其他的transaction從資料系統內非常不同的地方來粉問這些資料,觸發了buffer flush to disk,並從disk讀取的動作)
總之,用戶就算對table做了一堆改變並且觸發一堆commit,都不見得會馬上反映在底層的data fields. 而是會先反映在稱為Write Ahead Log(WAL) buffer的領域之內,然後再同步到WAL中。
Dirty標籤
在 PostgreSQL 中,isdirty 或称为 t_data->t_infomask & HEAP_XMAX_INVALID 是一個在資料庫 tuple 層級使用的標誌,用於指示一個 tuple 是否已標記為不乾淨的。
附註: Tuple的意思其實就是Row
A tuple in the context of databases refers to an ordered set of data elements stored together as a single entity within a table. In simple terms, it represents a row in a database table. Each tuple represents a unique instance of an entity or an object being described in the database. For example, in a table representing employees, each tuple or row would contain data related to a specific employee, such as their name, ID, address, and so on.
當 tuple 被更新或刪除操作修改但尚未寫入磁碟時,該 tuple 被認為是”髒”的。當 tuple 被修改時,PostgreSQL 會使用交易 ID(XID)對其進行標記,以跟踪更改。isdirty 標誌用於在檢查點或惰性寫入程序期間快速確定是否需要將 tuple 寫回磁碟。
如果設置了 isdirty 標誌,意味著 tuple 已被修改並需要刷新到磁碟中,以確保更改是持久的。如果未設置該標誌,則該 tuple 被視為乾淨,表示更改已經寫入磁碟。
isdirty 標誌是 tuple 元數據的一部分,由 PostgreSQL 在內部使用,用於性能優化和有效管理寫入過程。它不直接由用戶訪問或控制。
CheckPoint
這是一種強制性的行程,但在討論這個之前要先理解blocks的概念。
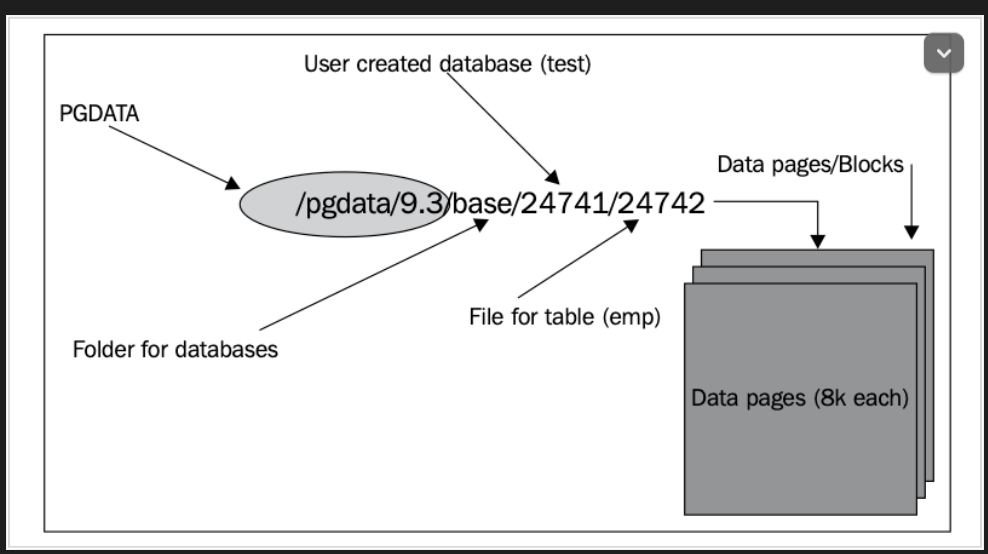
Postgres在處理資料的時候是以blocks為單位,假設插入一筆簡單的資料:
test=# create table emp(id serial, first_name varchar(50));
test=# insert into emp(first_name) values('Javadeva');
這個資料理論上只會佔有幾bytes而已,但是實際上他所在的位置站了8kb
這就是因為Postgres是以block為單位在處理資訊,你也可以稱這個為Page
驗證的方式可以透過pg_relation_filepath(TABLE_NAME),找到該table在base底下的路徑,用ls指令去偷看他的大小
root@613f786b1b6d:/var/lib/postgresql/data# ls -la base/16687/16701
-rw------- 1 postgres postgres 8192 Jul 17 13:58 base/16687/16701
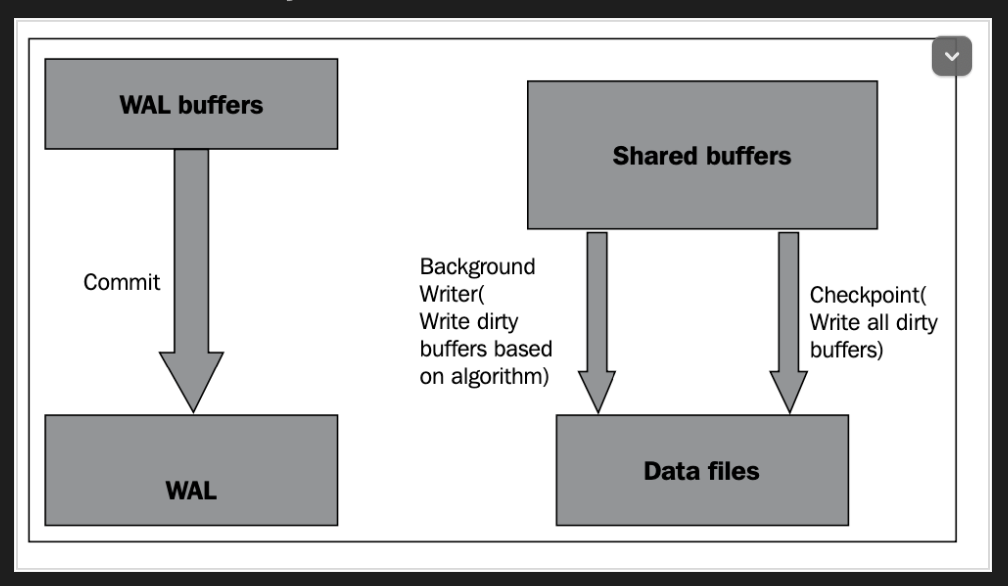
先前提到的使用者提交上來的資料,不會馬上反應到實體硬碟上面去,這個工作就是由checkpoint process來處理的。
當checkpoint發生的時候,所有的dirty pages會被寫入table與index檔案裡面。然後被改成clean的狀態。同時更新WAL(Write-ahead log)。
因為截至目前為止的更新狀態都會被寫進去剛剛說的WAL,假設系統今天崩潰掉的話,復原程序就會來看著個log裡面最新的checkpoint紀錄,來決定如何執行REDO操作。在復原之後,在把「復原」這個動作的log刪掉。
誰來決定checkpoint什麼時候觸發?
- checkpoint_segments
- checkpoint_timeout
- checkpoint_ completion_target.
WAL & WAL Write Process
當對一個row的改變進行提交後,這份commit會被送到WAL segments內處理。
我們可以在pg_xlog內找到這些訊息(之後的版本改到pg_wal了)
觀察下面的檔案可以看到一個segments帶有16MB的容量
segment是由大小為8k的block組成,也就是說一個seg可以有2048個block
Usually, each segment is 16 MB (megabytes) in size, which is equivalent to 2,048 blocks of 8 KB. Once a segment is completely filled with data, PostgreSQL switches to a new segment and continues writing the WAL records to the new segment.
注意不要跟base底下的block搞混,這裡的block是用來處理log而非正式的資料。
In the write-ahead log, a
blockrefers to a fixed-size unit of data (usually 8 KB) that is used to store transaction log records. These blocks are part of the WAL files, which are separate from the actual data files in the/pgdata/base/directory.On the other hand, theblockfiles under the/pgdata/base/directory contain the actual data pages of the database. These files store the table and index data in the PostgreSQL database.
WAL的3種用途
- Recovery
- Snapshot
- Replication
All the changes happening in the server are being recorded in the WAL segments anyway. Why not use these and get a stand-by server ready for failover?
- 除此之外也降低了disk的寫入負擔
你可以透過grep wal postgresql.conf去看一下針對wal_的設定。
其中最重要的是wal_level,他會直接影響我們可以對WAL做哪些事情
這裡的flush時間也不要跟checkpoint搞混,這裡flush出去的是log不是data。
通常WAL的同步次數會比checkpoints還要頻繁
Another decision is how frequently the WAL writer should flush WAL to disk. What we need to remember is that this will be far more frequent than checkpoint frequency. The WAL flush interval is indicated by wal_writer_delay. The default value is 200 milliseconds.